摘要
当上下文窗口、成本与数学能力成为关键决策因子,如何快速锁定适配模型?本文通过12项核心指标的三层漏斗筛选法,拆解两类主流模型的真实场景适配性。
一、参数对比为何成为技术团队的效率黑洞?
2025年全球可调用大模型超300个,但选型面临三重困境:
单位混乱:上下文长度用token/page/char混合标注
动态定价:价格调整周期快于企业采购流程
指标超载:87%团队无法量化“数学指数提升1分”的业务价值
结果:平均选型周期从30天延长至90天,决策成本飙升300%。
二、三层漏斗筛选法:从300+模型到精准匹配
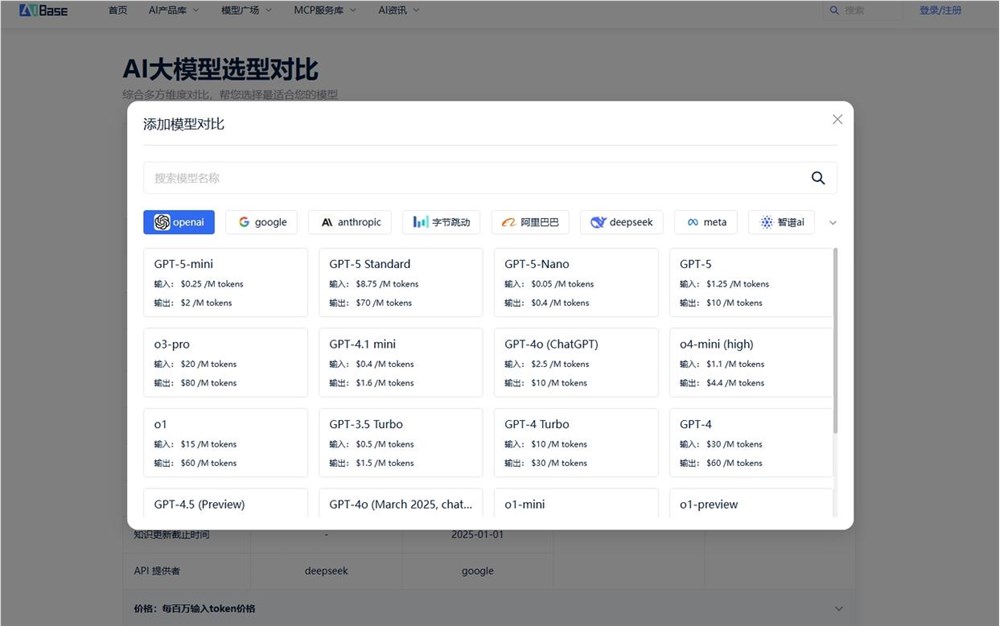
通过AIbase引擎验证的决策路径:
场景刚需(排除80%选项)
↓
性能底线(验证核心能力)
↓
边际增益(评估溢价合理性)
以Gemini2.5Flash-Lite与DeepSeek R1实测为例:
关键差异雷达图(数据同步2025-08-13)

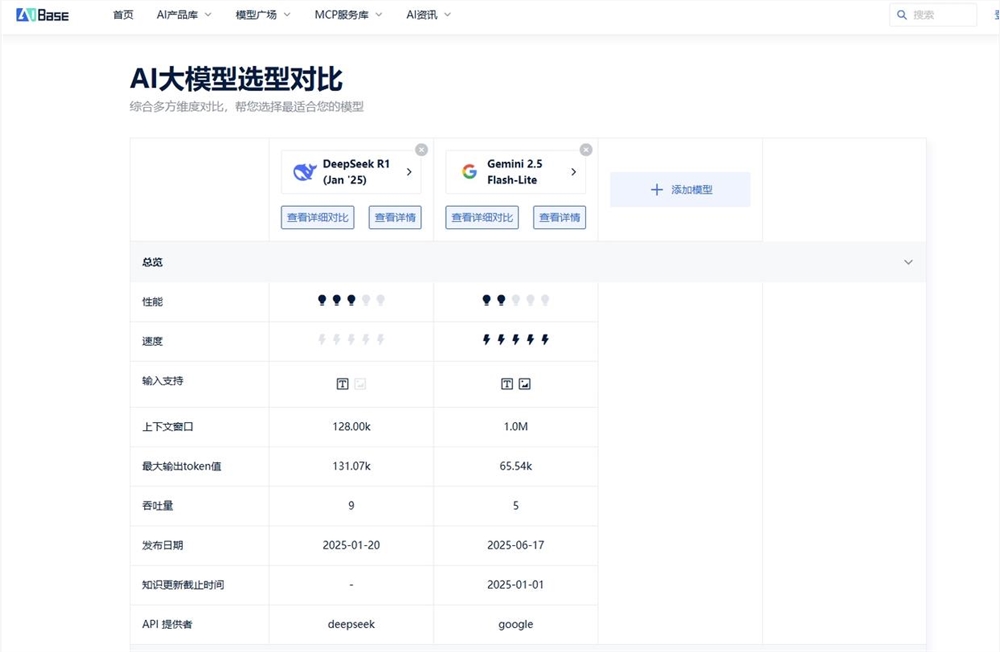
三、企业级决策实战:FAQ机器人选型
需求背景:200页技术手册解析,日处理10M tokens,响应<2秒
决策漏斗生效过程:
1.场景刚需过滤
上下文≥200k → 保留12个模型
成本≤$0.5/M → 剩余3个(Gemini居首)
响应>100tok/s → Gemini直接达标
2.性能底线验证

3.边际增益决策
选Gemini:年省$16,000(≈2张A100)
选DeepSeek:金融计算场景人工复核降低15%
结论:常规FAQ选Gemini,含数值计算选DeepSeek
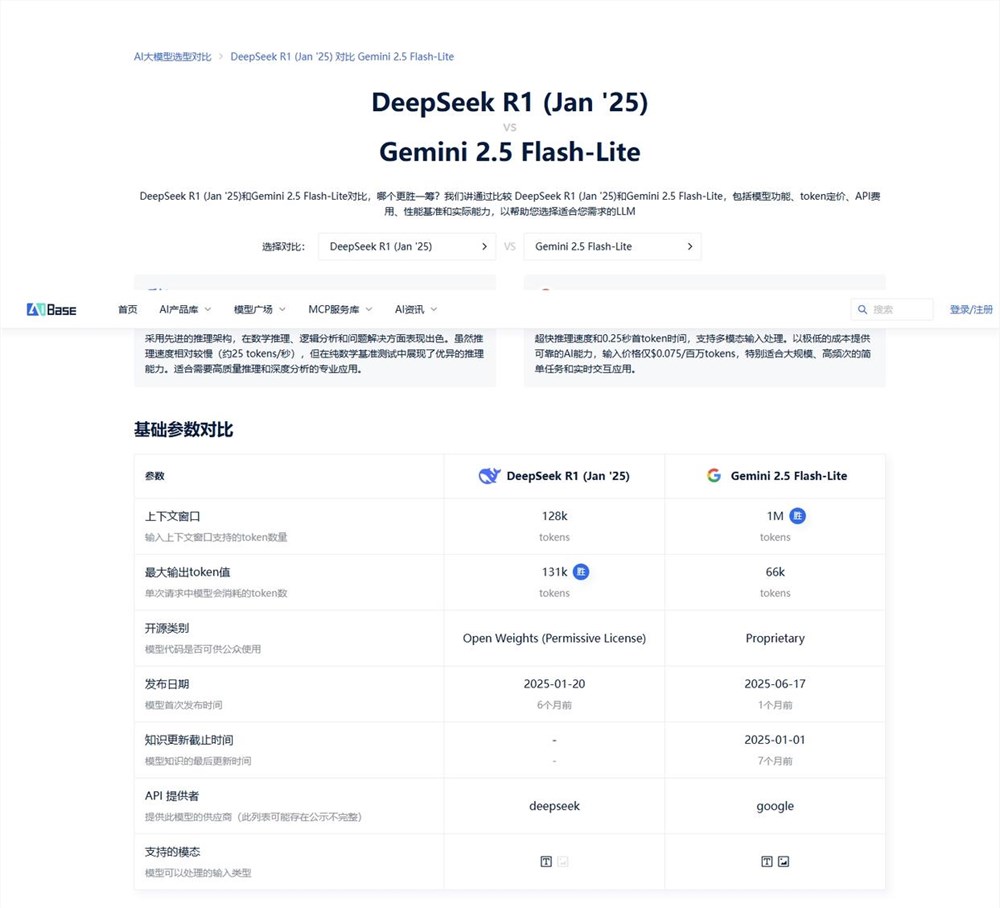
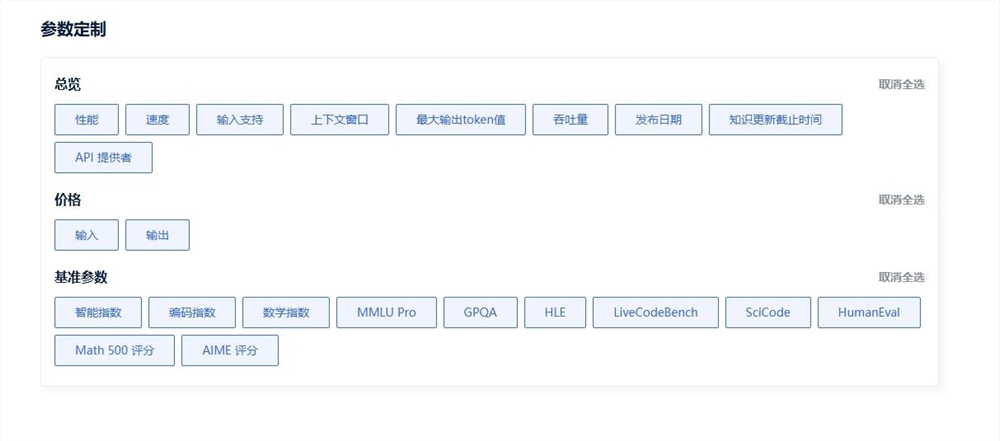
四、如何实现可复用的选型方法论
1.打开模型对比平台→ 设定「上下文/成本/核心能力」阈值
2.生成动态PDF报告(含成本模拟曲线)
3.嵌入产品需求文档→ 建立选型基线
某跨境电商团队验证:将3小时会议压缩至18分钟,错误选型率下降40%
五、工具价值的本质:为决策熵减
当技术选型从参数争论转向场景验证:
工程师资源聚焦提示词优化而非参数表校对
版本迭代时可追溯历史决策依据
成本波动自动触发重新评估(如价格波动超15%)
决策效率公式:
(模型数量× 参数维度)÷ 场景过滤器 = 可执行结论
用AIbase 把“综合多方维度对比”拆成3个按钮,本质上是在为公司节省工程师最昂贵的时间。
当你把3小时会议缩短到10分钟,团队就能把精力放在提示词优化与产品体验,而不是对着参数表吵架。